
Pythonを使ったデータ前処理で、必要そうな処理を確認していきます。(私の備忘も兼ねています)
使用ライブラリはPandasです。Jupyter NoteBook 使うことを想定してます。なお、本記事では前置き(前処理は何か、Pandasとは何か etc)はせず、使う頻度が高そうなコードをとにかく羅列していきます。詳細な引数の説明とか色々割愛してます。チートシート的に使ってください。
設定・前準備
モジュールインポート
【構文】
import (モジュール名) as (別名)
モジュール(ライブラリともいう)をインポートします。これしないと動きません。下でインポートしているものは適当なので必要に応じて追加してください。オブジェクト(関数や変数、クラス)をインポートする場合はfrom … import を使います。
import numpy as np import pandas as pd import matplotlib.pyplot as plt from sklearn import datasets
CSVインポート(pandasのDataFrameの形で読み込む)
【構文】
(インポート先変数) = pd.read_csv(“(インポートファイルのフルパス)”)
df = pd.read_csv("c:\\data\\df.csv")
PandasのDataFrameに変換
【構文】
(変換先データの変数) = pd.DataFrame(変換元データ名, columns=[列名], index=[行名])
引数のcolumnsとindexは省略可。
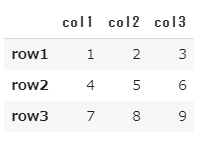
ar = np.array([[1,2,3],[4,5,6],[7,8,9]])
df = pd.DataFrame(ar, columns=["col1","col2","col3"], \
index=["row1","row2","row3"])
df
EDA(探索的データ解析)
使用データはおなじみKaggleのタイタニックのテストデータです。
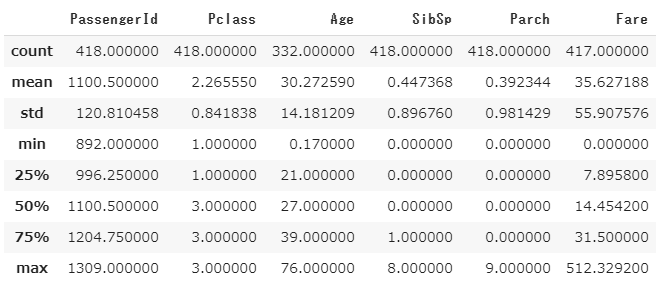
データの特徴量(describe)
主要な特徴量を出力します。データを取得したらまず最初にみるべきことです。
df.describe()
行数・列数(shape)
(行数, 列数)を出力します。
df.shape
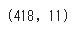
先頭行確認(head)
先頭5行を出力します。head()の()内に数値を入れることで、表示したい行数を指定できます。
df.head()

末尾行確認(tail)
末尾5行を出力します。headと同じ。
df.tail()

列名(項目名)確認(columns)
df.columns
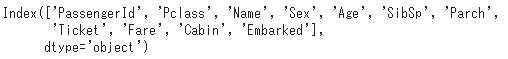
項目の型確認(dtypes)
df.dtypes

ヒストグラム描写(hist)
ヒストグラムを描写します。各項目の数値のばらつきを見るうえで必須。下記は年齢のヒストグラムを描写。
import matplotlib.pyplot as plt plt.hist(df['Age'], bins=10) # binsはヒストグラムの棒の数を指定する
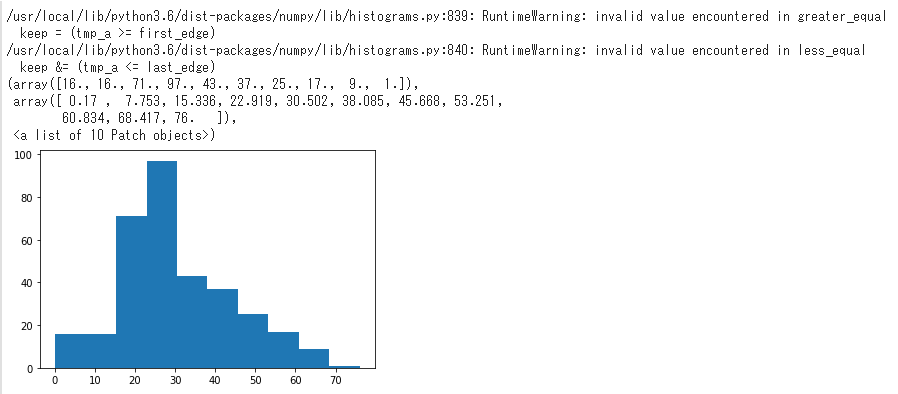
引数詳細はここを参照。
相関行列(corr)
目的変数との相関や、説明変数間の多重共線性を見るうえで便利。
df2.corr()
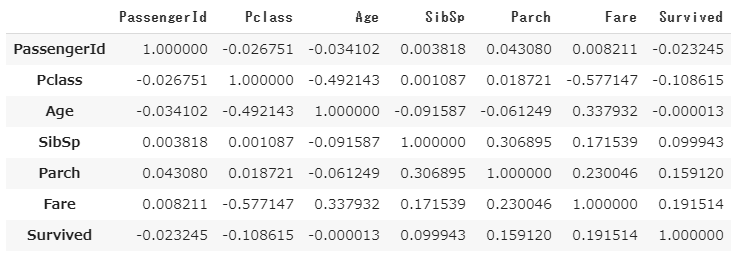
上図から目的変数「Survived」は「Fare」と0.159120の相関係数をもつので、わずかに相関関係があることがわかります。
データ加工
ソート(sort_values)
1項目でソート
df2.sort_values('Age')
複数項目でソート
df2.sort_values(['Age', 'Fare'])
降順でソート
引数ascendingをFalseに指定しましょう。
df2.sort_values('Age', ascending=False)
抽出
特定の行を条件抽出
下記は20歳を上回るデータを抽出。
df2[df2['Age']>20]
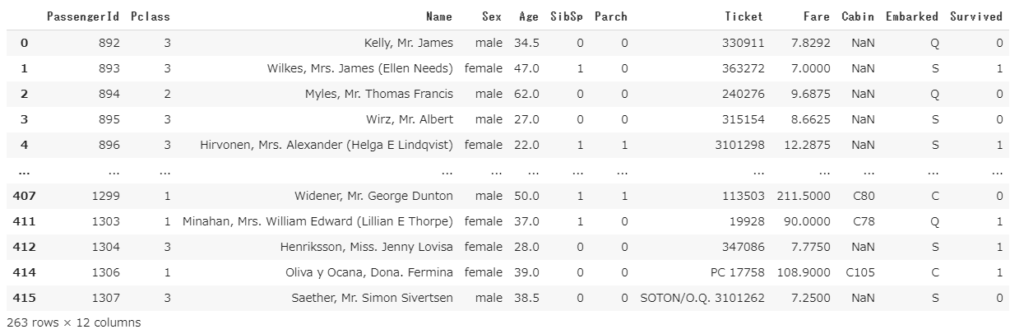
特定の文字列を含む、という条件を付けたい場合はstr.contains()を使います。下記は名前に「Smith」を含むデータを抽出しています。
df2[df2['Name'].str.contains("Smith")]

特定の列を抽出
特定列を抽出
df2[{'Age', 'Fare'}]
特定の条件で行列を抽出
locを使います。一つ目の引数に条件を指定し、二つ目の引数に列名を指定します。
locの詳細はこちらの説明が詳しいので参考に。
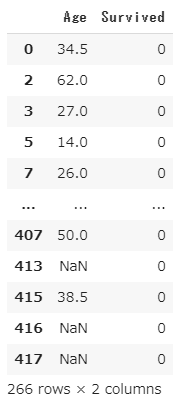
下記は「Survived」= 0 のデータに限定したうえで「Age」と「Survived」の列を抽出。
df2.loc[df2['Survived']==0, {'Age', 'Survived'}]
削除(drop)
dropを使うのがいいでしょう。
行削除
drop()のカッコ内に行インデックスを指定します。
df2.drop(3) # 行インデックス = '3' の行を削除
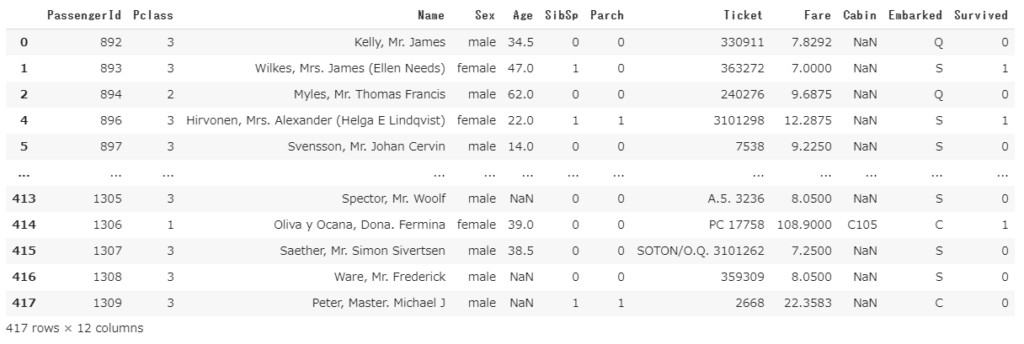
行インデックス(左端の列) = ‘3’の行が削除されていることがわかると思います。上記の行インデックスはたまたま数値ですが、文字列の場合も同じように指定します。
列削除(axis=1)
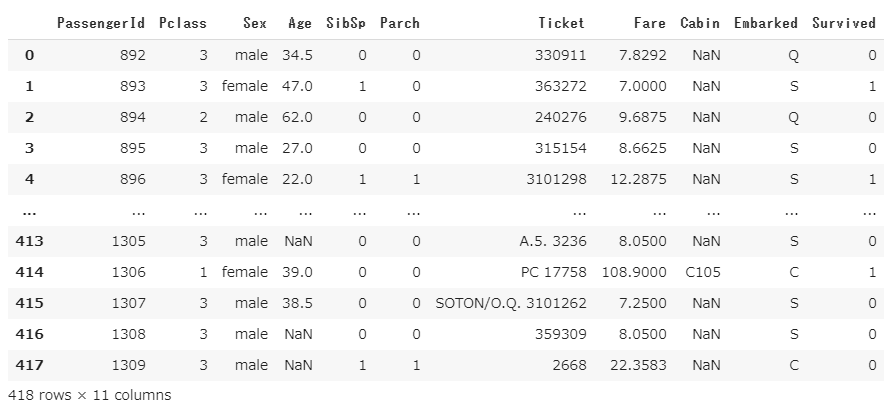
dropの第2引数にaxis=1を入れます。axisは0のときは行、1のときは列を意味しますが、デフォルトは0なので行削除の時は省略可能です。今回は列削除なので、axis=1の指定が必須。下記コードはName列を削除するものです。
df2.drop('Name', axis=1)
重複行削除(drop_duplicates)
drop_duplicatesメソッドを使います。下記コードは全列が重複していた場合に削除しています。
df2.drop_duplicates()
項目指定(subset)
重複項目を指定したい場合は引数subsetを指定します。下記コードは項目’Pclass’、’Sex’が重複しているレコードは最初の1件を除いて削除しています。
df2.drop_duplicates(subset=['Pclass', 'Sex'])

重複行削除後の残存レコードの指定
重複しているレコードのうち、最後を残したい場合は引数keepに’last’を指定しましょう。(keepのデフォルトは’first’です。これは重複しているもののうち最初のレコードを残します)
df2.drop_duplicates(subset=['Pclass', 'Sex'], keep='last')
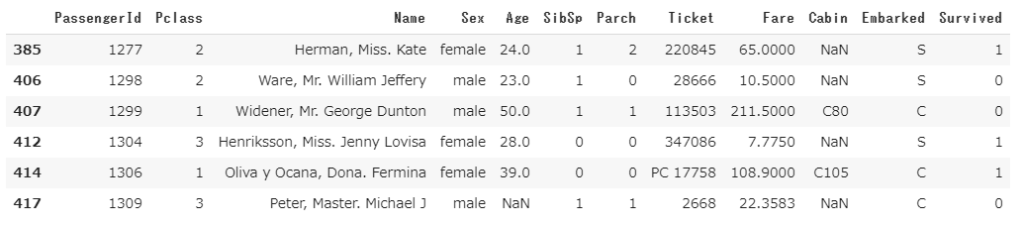
keepを指定しない時と比べて左端列のインデックス番号が大きいことがわかると思います。
結合(merge)
二つのデータを結合するときはpandasのmergeメソッドを使います。
【構文】
pd.merge(結合対象データ名1, 結合対象データ名2, on=, how=)
引数on について
結合するキーとなる列名を指定します。列名が二つのデータで共通しない場合はleft_on、right_onの引数にそれぞれ指定します。指定しない場合は両データで列名が共通している列が自動的に選ばれます。
引数howについて
結合方法を指定します。
内部結合(inner_join): how=’inner’
左結合(left_join): how=’left’
右結合(right_join): how=’right’
外部結合(outer_join): how=’outer’
デフォルトは’inner’になります。
実用例
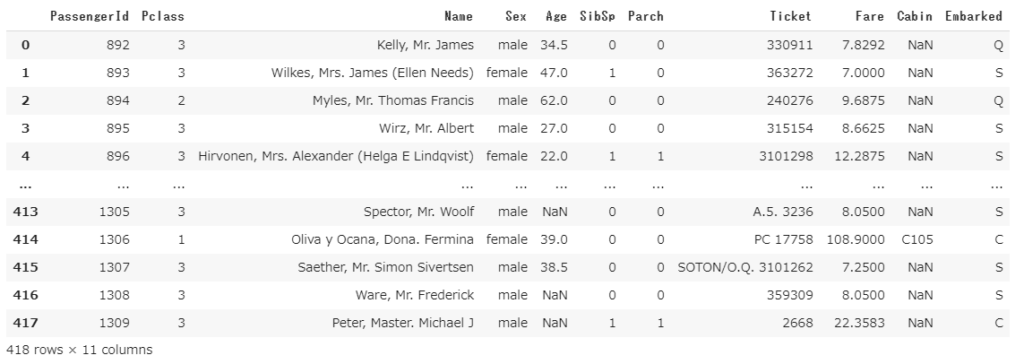
タイタニックのtestデータ(説明変数を格納)、生死データ(目的変数を格納)をマージしてみます。
#testデータ
df = pd.read_csv("test.csv")
df
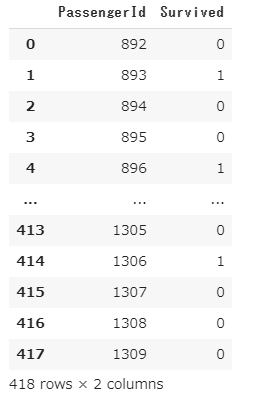
#生死データ
result = pd.read_csv("gender_submission.csv")
result
上記二つのデータを結合します。
df2 = pd.merge(df, result, how='left', on='PassengerId')
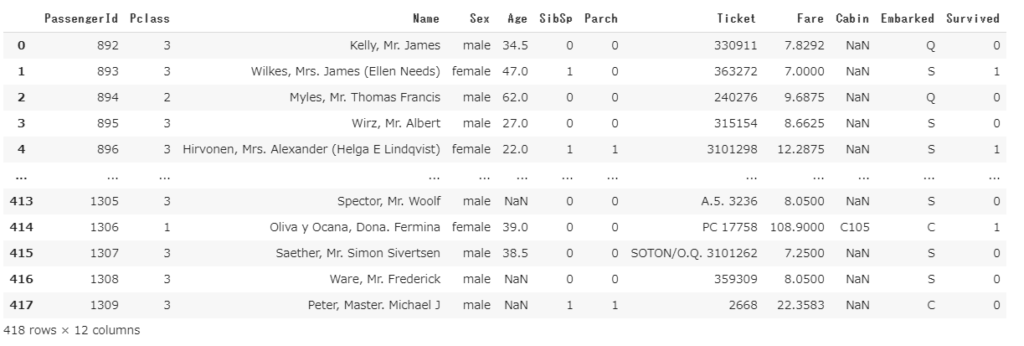
生死データの項目’Surviverd’が右端列に追加されているのが確認できるかと思います。
mergeの詳細についてはこちらのページが詳しいです。
集計(groupby)
簡単な集計であれば、下記コードのようにgroupbyを使えば可能です。性別別の各項目の平均値を出しています。
df2.groupby('Sex').mean()

ただし、上記の場合はキー項目となる”Sex”がインデックスになってしまうので、それを避けたい場合はas_index=False を指定しましょう。
実際には項目を限定して、平均や合計など集計方法を変えて算出したいことが多いと思います。その場合はaggを使って、項目ごとに集計方法を指定します。下記コードは性別別の生存者数、平均年齢、運賃の中央値をそれぞれ出しています。
df2.groupby('Sex').agg({'Survived': np.sum, 'Age': np.mean, 'Fare':np.median})
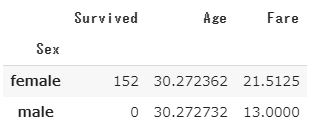
男性の生存者が0名になっているのが不自然ですが、元データを直接見てもそうだったので、元々そういうデータなのでしょう。
型変換
pandasのDataFrameの型変換を行う場合はastypeを使います。項目内にNaNなどが入っているとエラーになるので注意しましょう。下記コードはfloat型になっている項目’Age’をint型に変更しています。
df3 = df2.dropna(subset=['Age']) # 年齢が欠損値のレコードを削除 df3['Age'].dtypes
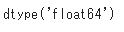
df_tmp = df3.astype({'Age':'int'})
df_tmp['Age'].dtypes
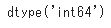
欠損値処理
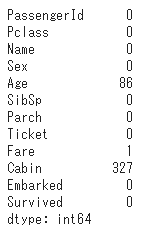
欠損値確認(isnull().sum())
isnullとsumの組み合わせで素早く欠損値の数を確認することができます。
df2.isnull().sum()
欠損値削除(dropna)
欠損値があるレコードを削除するにはdropnaを使います。特定の列を指定する場合は引数subsetに列名を指定します。その場合は指定した項目に欠損値があった場合のみ削除します。subsetの指定は全てリストで行う必要があることに注意してください。
df2.dropna(subset=['Age']) # 年齢が欠損値のレコードを削除
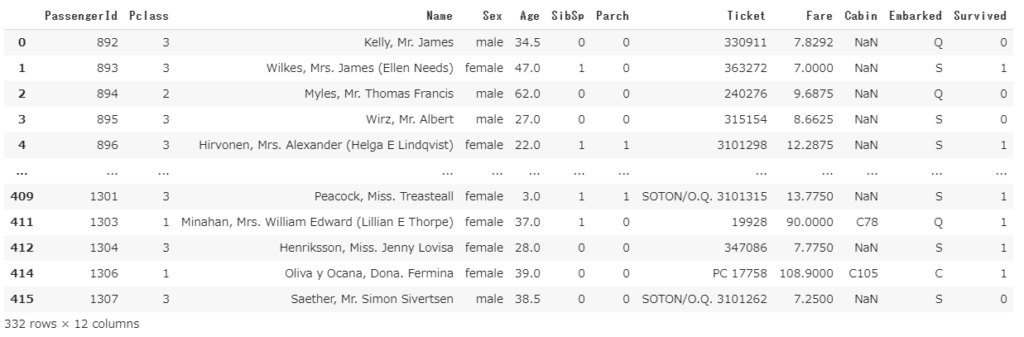
なにかしらの項目が欠損値であった場合はとにかく削除したい、という場合は引数の指定をなくせば可能です。
df2.dropna()
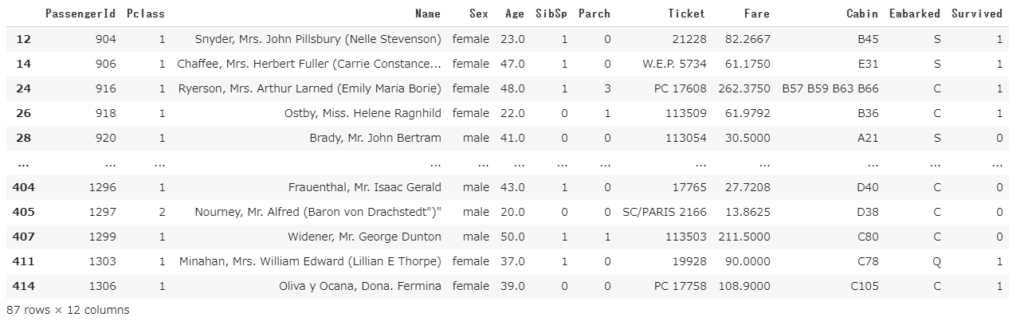
欠損値補完(fillna)
欠損値補完にはfillnaメソッドを使います。
df2
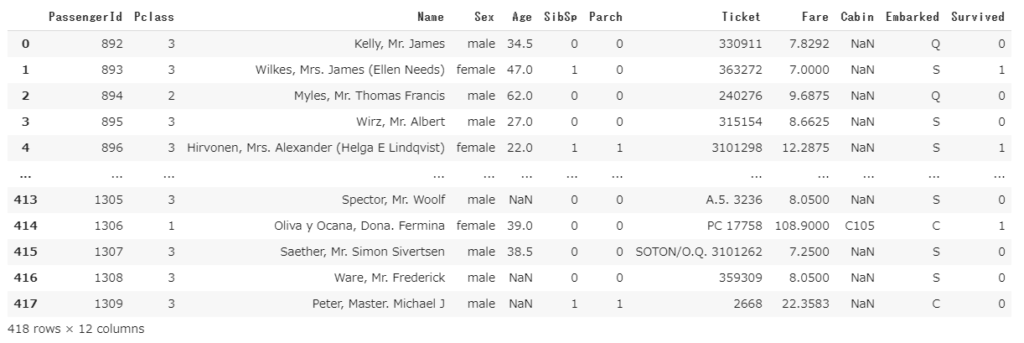
# 欠損値に一律ゼロを入れる場合 df2.fillna(0)
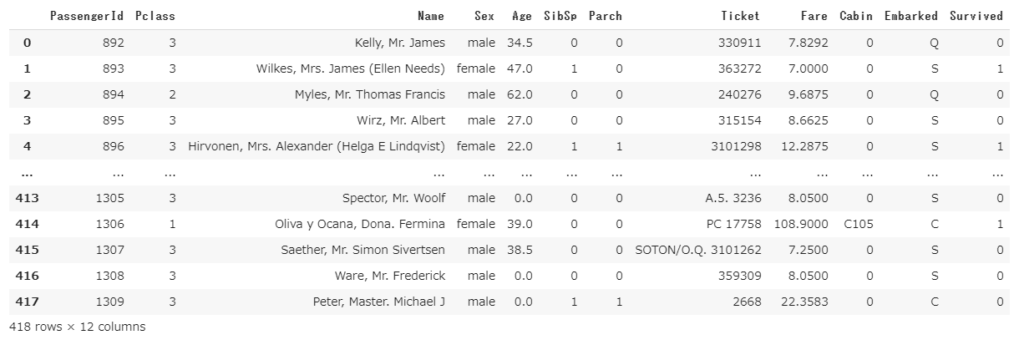
# 列を指定して、それぞれ別の値を入れる場合は辞書で指定
df2.fillna({'Age': 0, 'Cabin': 'XXX'})
対数変換・正規化
※ここの項目は後日追記したものなので、全く別のデータ使っています。
対数変換 基本
対数変換は分析対象のデータの数値の広がりが大きいときに使います。
例えば、年収を分析するときに年収100万円と1000万円と1億円の人が混在していた場合、1000万円と1億円のあいだには9000万円の差がありますが、100万円と1000万円では900万円と10倍の差があります。
しかし、分析に与える影響の大きさが10倍になるわけではありません。(恐らく与えるインパクトは同じくらい。)
それでもヒストグラムで可視化するときや線形回帰などのモデル作成をするときには10倍の差がそのままでてしまうので、正確な分析の妨げになります。対数変換はこの弊害を解消するための手段となります。
コードは以下の通り。PandasのDataFrameの形だとやりにくいのでいったんnumpy配列に戻してから変換しています。
a = pandas_df.values log_a = np.log(a) ## 底をeとするaの対数 log2_a = np.log2(a) ## 底を2とするaの対数 log10_a = np.log10(a) ## 底を10とするaの対数
対数変換 neglog変換
対象のデータに負の数や0を含む数を対数変換するときに使用します。
## pandas だと対数変換がやりにくいのでnumpy配列にいったん返還する np_balance = train["balance"].values np_balance = np.sign(np_balance) * np.log1p(np.abs(np_balance)) train["balance_log"] = np_balance
数式で書くと
符号(+1 or -1) × log(対象値の絶対値 + 1)
となります。
ポイントは符号を掛け算することで負の数を表現することと、対数変換の数値に1を加えることで、0だったときのエラーを避けているということですね。
正規化
絶対値
符号の取得
その他
ダミー変数化(get_dummies)
質的変数を0 or 1の数値に置き換える手法をダミー変数といいます。質的変数を分析するうえで必須のテクニックです。
# 性別をダミー変数化 pd.get_dummies(df2, drop_first=True, columns=['Sex'], dummy_na=True)
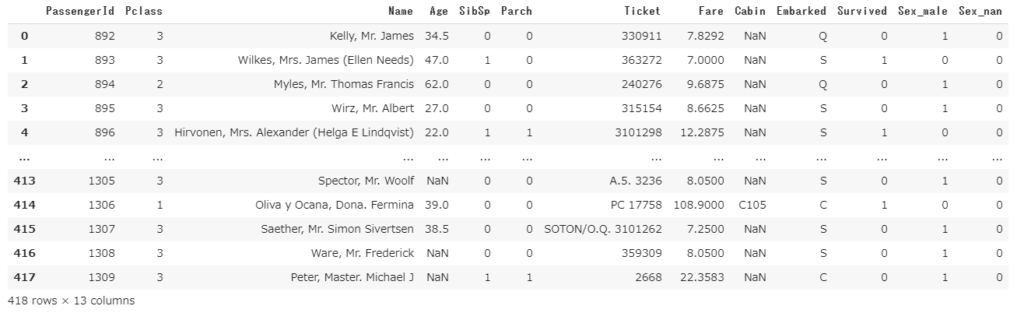
右端列にダミー変数化された”Sex~”の項目が追加されていることがわかります。
以下、引数について解説します。
drop_first
k個の質的変数を説明するためには、k-1個の変数があればよいです。例えば、男性と女性の2種類を判別するためには、男性である=1、男性でない=0という1種類の変数で説明することができます。デフォルトのget_dummiesメソッドはk個の変数を作成してしまいますが、drop_firstの引数をTrueに指定すればk-1個の変数だけ作成してくれます。上記のケースだとSex_femaleの列が削除されています。
columns
ダミー変数化したい列を指定します。
dummy_na
欠損値も一つのカテゴリーとしてダミー変数化するかどうかを決めます。上記の例ではSex_nanでそれを表現しています。
データ書込(CSV出力)
to_csvでいけます。
df2.to_csv('out.csv')
以上。おおよそ、細かい部分はかなり割愛してますが前処理に必要な処理は網羅したはずです。また随時、補足・追加していきますね。
最近のコメント